ByoTrack fundamental features
[1]:
import cv2
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import torch
import byotrack
TEST = True # Set to False to analyze a whole video
Loading a video
[2]:
video_path = "path/to/video.ext"
# Simply open a video
video = byotrack.Video(video_path)
fps = 20
# fps = video.reader.fps
# Note: video could also be a 4 dimensionnal numpy array loaded manually
[3]:
# A transform can be added to normalize and aggregate channels
transform_config = byotrack.VideoTransformConfig(aggregate=True, normalize=True, q_min=0.01, q_max=0.999)
video.set_transform(transform_config)
# Show the min max value used to clip and normalize
print(video._normalizer.mini, video._normalizer.maxi)
[401.] [1016.]
[4]:
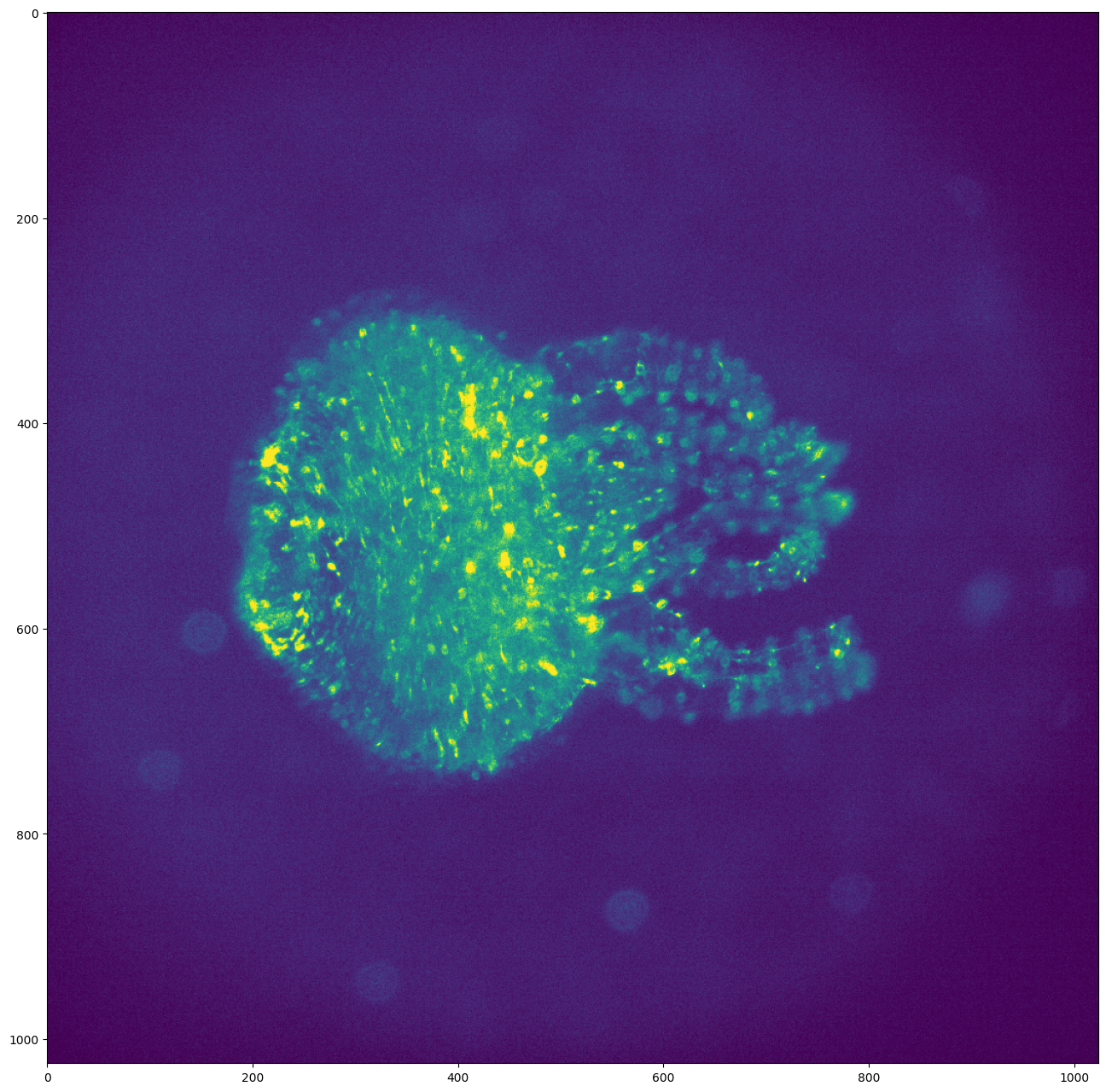
# Display the first frame
plt.figure(figsize=(24, 16), dpi=100)
plt.imshow(video[0])
plt.show()
[5]:
# Visualisation of the whole video with opencv
for i, frame in enumerate(video):
# Display the resulting frame
cv2.imshow('Frame', frame)
cv2.setWindowTitle('Frame', f'Frame {i} / {len(video)}')
# Press Q on keyboard to exit
key = cv2.waitKey(1000 // fps) & 0xFF
if key == ord('q'):
break
if cv2.getWindowProperty("Frame", cv2.WND_PROP_VISIBLE) <1:
break
# Closes all the frames
cv2.destroyAllWindows()
Detections on a video: Example of WaveletDetector
[6]:
# Create the detector object with its hyper parameters
from byotrack.implementation.detector.wavelet import WaveletDetector
detector = WaveletDetector(scale=1, k=3.0, min_area=3, batch_size=20, device=torch.device("cpu"))
[7]:
# Run the detection process on the current video
if TEST: # Use slicing on video to run detection only on a part of it
detections_sequence = detector.run(video[:50])
else:
detections_sequence = detector.run(video)
Detections (Wavelet): 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:03<00:00, 15.35it/s]
[8]:
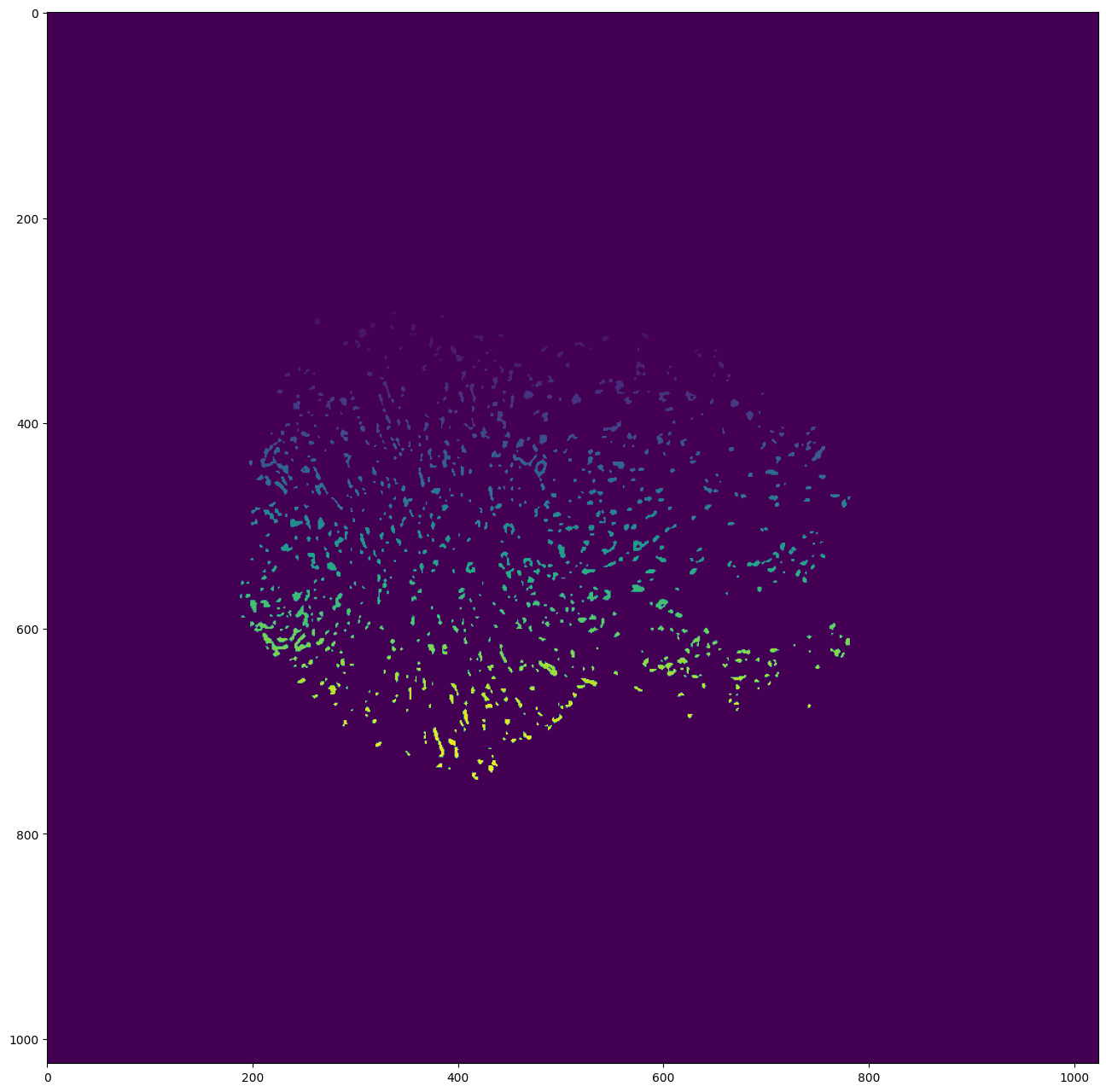
# Display the first detections
segmentation = detections_sequence[0].segmentation.clone()
segmentation[segmentation!=0] += 50 # Improve visibility of firsts labels
plt.figure(figsize=(24, 16), dpi=100)
plt.imshow(segmentation)
plt.show()
[9]:
# Display the detections with opencv
# Use w and x to move backward/forward in the video
i = 0
while True:
mask = (detections_sequence[i].segmentation.numpy() != 0).astype(np.uint8) * 255
# Display the resulting frame
cv2.imshow('Frame', mask)
cv2.setWindowTitle('Frame', f'Frame {i} / {len(detections_sequence)} - Number of detections: {detections_sequence[i].length}')
# Press Q on keyboard to exit
key = cv2.waitKey() & 0xFF
if key == ord('q'):
break
if cv2.getWindowProperty("Frame", cv2.WND_PROP_VISIBLE) <1:
break
if key == ord("w"):
i = (i - 1) % len(detections_sequence)
if key == ord("x"):
i = (i + 1) % len(detections_sequence)
cv2.destroyAllWindows()
[10]:
# Set hyperparameters manually on the video
# Use w/x to move backward/forward in the video
# Use c/v to update k (the main hyperparameter)
# You can restard with another scale/min_area
K_SPEED = 0.01
i = 0
detector = WaveletDetector(scale=1, k=3.0, min_area=3.0, device=torch.device("cpu"))
while True:
frame = video[i]
detections = detector.detect(frame[None, ...])[0]
mask = (detections.segmentation.numpy() != 0).astype(np.uint8) * 255
# Display the resulting frame
cv2.imshow('Frame', mask)
cv2.setWindowTitle('Frame', f'Frame {i} / {len(video)} - k={detector.k} - Num detections: {detections.length}')
# Press Q on keyboard to exit
key = cv2.waitKey() & 0xFF
if key == ord('q'):
break
if cv2.getWindowProperty("Frame", cv2.WND_PROP_VISIBLE) <1:
break
if key == ord("w"):
i = (i - 1) % len(video)
if key == ord("x"):
i = (i + 1) % len(video)
if key == ord("c"):
detector.k = detector.k * (1 - K_SPEED)
if key == ord("v"):
detector.k = detector.k * (1 + K_SPEED)
cv2.destroyAllWindows()
Link detections: Example of IcyEMHTLinker
[11]:
from byotrack.implementation.linker.icy_emht import IcyEMHTLinker
# Create the linker object with icy path
# This Linker requires to install Icy software first
icy_path = "path/to/icy_dir/"
linker = IcyEMHTLinker(icy_path)
[12]:
# You can set the expected motion of particles
linker.motion = linker.Motion.BROWNIAN # Already by default
[13]:
# Run the linker given a video (Unused) and detections
if TEST: # Use slicing to run linker only on a part of the data
tracks = linker.run(video, detections_sequence[:50])
else:
tracks = linker.run(video, detections_sequence)
Calling Icy with: java -jar icy.jar -hl -x plugins.adufour.protocols.Protocols protocol=/home/rreme/workspace/pasteur/byotrack/byotrack/implementation/linker/icy_emht/emht_protocol.xml rois=/home/rreme/workspace/pasteur/byotrack/docs/source/run_examples/_tmp_rois.xml tracks=/home/rreme/workspace/pasteur/byotrack/docs/source/run_examples/_tmp_tracks.xml directed=0 multi=0
Initializing...
OpenJDK Runtime Environment 11.0.19+7-post-Ubuntu-0ubuntu120.04.1 (64 bit)
Running on Linux 5.15.0-73-generic (amd64)
Number of processors : 16
System total memory : 32.7 GB
System available memory : 9.4 GB
Max java memory : 8.2 GB
Image cache initialized (reserved memory = 3189 MB, disk cache location = '/tmp/icy_cache')
Headless mode.
java.lang.UnsatisfiedLinkError: /home/rreme/workspace/pasteur/icy_build/lib/unix64/vtk/libvtkRenderingCoreJava.so: libjawt.so: cannot open shared object file: No such file or directory
Cannot load VTK library...
Icy Version 2.4.3.0 started !
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by icy.util.ReflectionUtil (file:/home/rreme/workspace/pasteur/icy_build/icy.jar) to field java.lang.ClassLoader.usr_paths
WARNING: Please consider reporting this to the maintainers of icy.util.ReflectionUtil
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Loading workflow...
Track extraction at frame 49
Exiting...EHCache disposed
Image cache shutdown..
done
[14]:
# Visualize tracks existence in time
# Transform into tensor
tracks_tensor = byotrack.Track.tensorize(tracks)
print(tracks_tensor.shape) # N_frame x N_track x D
mask = ~ torch.isnan(tracks_tensor).any(dim=2)
plt.figure(figsize=(24, 16), dpi=100)
plt.xlabel("Track id")
plt.ylabel("Frame")
plt.imshow(mask)
plt.show()
torch.Size([50, 1423, 2])

[15]:
# Visualize tracks with opencv
# Use w/x to move backward/forward in the video (or space to run the video)
# Use c to display also the detections on the frame
fps = 20
running = False
display_detections = False
# Build a color map
hsv = mpl.colormaps["hsv"]
colors = list(map(lambda x: tuple(int(c * 255) for c in x[:3]), map(hsv, [i / 200 for i in range(200)])))
frame_id = 0
while True:
frame_id += running
frame = (video[frame_id] * 255).astype(np.uint8)
if display_detections and frame_id < len(detections_sequence):
mask = (detections_sequence[frame_id].segmentation.numpy() != 0).astype(np.uint8) * 255
frame = np.concatenate((mask[..., None], frame, np.zeros_like(frame)), axis=2)
else:
frame = np.concatenate((np.zeros_like(frame), frame, np.zeros_like(frame)), axis=2)
# Add tracklets
for track in tracks:
point = track[frame_id]
if torch.isnan(point).any():
continue
i, j = point.round().to(torch.int).tolist()
color = colors[track.identifier % 200]
cv2.circle(frame, (j, i), 5, color)
cv2.putText(frame, str(track.identifier % 10), (j + 4, i - 4), cv2.FONT_HERSHEY_SIMPLEX, 0.3, color)
# Display the resulting frame
cv2.imshow('Frame', frame)
cv2.setWindowTitle('Frame', f'Frame {frame_id} / {len(video)}')
# Press Q on keyboard to exit
key = cv2.waitKey(1000 // fps) & 0xFF
if key == ord('q'):
break
if cv2.getWindowProperty("Frame", cv2.WND_PROP_VISIBLE) <1:
break
if key == ord(" "):
running = not running
if not running and key == ord("w"): # Prev
frame_id = (frame_id - 1) % len(video)
if not running and key == ord("x"): # Next
frame_id = (frame_id + 1) % len(video)
if key == ord("c"):
display_detections = 1 - display_detections
# Closes all the frames
cv2.destroyAllWindows()
Tracks refinement: Example of Cleaner, followed by EMC2 Stitcher
[16]:
from byotrack.implementation.refiner.cleaner import Cleaner
from byotrack.implementation.refiner.stitching import EMC2Stitcher
[17]:
# Split tracks with consecutive dist > 3.5
# Drop tracks with length < 5
cleaner = Cleaner(min_length=5, max_dist=3.5)
tracks = cleaner.run(video, tracks)
Cleaning: Split 254 tracks and dropped 219 resulting ones
Cleaning: From 1423 to 1458 tracks
[18]:
# Visualize tracks existence in time
# Transform into tensor
tracks_tensor = byotrack.Track.tensorize(tracks)
print(tracks_tensor.shape) # N_frame x N_track x D
mask = ~ torch.isnan(tracks_tensor).any(dim=2)
plt.figure(figsize=(24, 16), dpi=100)
plt.xlabel("Track id")
plt.ylabel("Frame")
plt.imshow(mask)
plt.show()
torch.Size([50, 1458, 2])

[19]:
# Stitch tracks together in order to produce coherent track on all the video
stitcher = EMC2Stitcher(eta=5.0) # Don't link tracks if they are too far (EMC dist > 5 (pixels))
tracks = stitcher.run(video, tracks)
Forward propagation: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49/49 [00:00<00:00, 393.95it/s]
Backward propagation: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49/49 [00:00<00:00, 384.54it/s]
Merging 1458 tracks into 1164 resulting tracks
[20]:
# Visualize tracks existence in time
# Transform into tensor
tracks_tensor = byotrack.Track.tensorize(tracks)
print(tracks_tensor.shape) # N_frame x N_track x D
mask = ~ torch.isnan(tracks_tensor).any(dim=2)
plt.figure(figsize=(24, 16), dpi=100)
plt.xlabel("Track id")
plt.ylabel("Frame")
plt.imshow(mask)
plt.show()
torch.Size([50, 1164, 2])

End-to-end tracking: Example of MultiStepTracker
[21]:
from byotrack import MultiStepTracker
[22]:
# Create all the steps: Detector, Linker[, Refiner]
# Then the tracker
detector = WaveletDetector(scale=1, k=3, min_area=3.0, batch_size=20, device=torch.device("cpu"))
linker = IcyEMHTLinker(icy_path)
# Optional refiner
refiners = []
if True:
refiners = [Cleaner(5, 3.5), EMC2Stitcher(eta=5.0)]
tracker = MultiStepTracker(detector, linker, refiners)
[23]:
if TEST: # Use slicing on video to run tracker only on a part of it
tracks = tracker.run(video[:50])
else:
tracks = tracker.run(video)
Detections (Wavelet): 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 50/50 [00:03<00:00, 15.44it/s]
Calling Icy with: java -jar icy.jar -hl -x plugins.adufour.protocols.Protocols protocol=/home/rreme/workspace/pasteur/byotrack/byotrack/implementation/linker/icy_emht/emht_protocol.xml rois=/home/rreme/workspace/pasteur/byotrack/docs/source/run_examples/_tmp_rois.xml tracks=/home/rreme/workspace/pasteur/byotrack/docs/source/run_examples/_tmp_tracks.xml directed=0 multi=0
Initializing...
OpenJDK Runtime Environment 11.0.19+7-post-Ubuntu-0ubuntu120.04.1 (64 bit)
Running on Linux 5.15.0-73-generic (amd64)
Number of processors : 16
System total memory : 32.7 GB
System available memory : 8.8 GB
Max java memory : 8.2 GB
Image cache initialized (reserved memory = 3189 MB, disk cache location = '/tmp/icy_cache')
Headless mode.
java.lang.UnsatisfiedLinkError: /home/rreme/workspace/pasteur/icy_build/lib/unix64/vtk/libvtkRenderingCoreJava.so: libjawt.so: cannot open shared object file: No such file or directory
Cannot load VTK library...
Icy Version 2.4.3.0 started !
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by icy.util.ReflectionUtil (file:/home/rreme/workspace/pasteur/icy_build/icy.jar) to field java.lang.ClassLoader.usr_paths
WARNING: Please consider reporting this to the maintainers of icy.util.ReflectionUtil
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
Loading workflow...
Track extraction at frame 49
Exiting...EHCache disposed
Image cache shutdown..
done
Cleaning: Split 254 tracks and dropped 219 resulting ones
Cleaning: From 1423 to 1458 tracks
Forward propagation: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49/49 [00:00<00:00, 382.08it/s]
Backward propagation: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49/49 [00:00<00:00, 449.09it/s]
Merging 1458 tracks into 1164 resulting tracks
[24]:
# Visualize tracks existence in time
# Transform into tensor
tracks_tensor = byotrack.Track.tensorize(tracks)
print(tracks_tensor.shape) # N_frame x N_track x D
mask = ~ torch.isnan(tracks_tensor).any(dim=2)
plt.figure(figsize=(24, 16), dpi=100)
plt.xlabel("Track id")
plt.ylabel("Frame")
plt.imshow(mask)
plt.show()
torch.Size([50, 1164, 2])

[25]:
# Visualize tracks with opencv
# Use w/x to move backward/forward in the video (or space to run the video)
# Use c to display also the detections on the frame
fps = 20
running = False
display_detections = False
# Build a color map
hsv = mpl.colormaps["hsv"]
colors = list(map(lambda x: tuple(int(c * 255) for c in x[:3]), map(hsv, [i / 200 for i in range(200)])))
frame_id = 0
while True:
frame_id += running
frame = (video[frame_id] * 255).astype(np.uint8)
if display_detections and frame_id < len(detections_sequence):
mask = (detections_sequence[frame_id].segmentation.numpy() != 0).astype(np.uint8) * 255
frame = np.concatenate((mask[..., None], frame, np.zeros_like(frame)), axis=2)
else:
frame = np.concatenate((np.zeros_like(frame), frame, np.zeros_like(frame)), axis=2)
# Add tracklets
for track in tracks:
point = track[frame_id]
if torch.isnan(point).any():
continue
i, j = point.round().to(torch.int).tolist()
color = colors[track.identifier % 200]
cv2.circle(frame, (j, i), 5, color)
cv2.putText(frame, str(track.identifier % 10), (j + 4, i - 4), cv2.FONT_HERSHEY_SIMPLEX, 0.3, color)
# Display the resulting frame
cv2.imshow('Frame', frame)
cv2.setWindowTitle('Frame', f'Frame {frame_id} / {len(video)}')
# Press Q on keyboard to exit
key = cv2.waitKey(1000 // fps) & 0xFF
if key == ord('q'):
break
if cv2.getWindowProperty("Frame", cv2.WND_PROP_VISIBLE) <1:
break
if key == ord(" "):
running = not running
if not running and key == ord("w"): # Prev
frame_id = (frame_id - 1) % len(video)
if not running and key == ord("x"): # Next
frame_id = (frame_id + 1) % len(video)
if key == ord("c"):
display_detections = 1 - display_detections
# Closes all the frames
cv2.destroyAllWindows()
Postprocessing: Fill NaN with interpolated values
[26]:
from byotrack.implementation.refiner.interpolater import ForwardBackwardInterpolater
[27]:
# After EMC2 stitching, NaN values can be inside merged tracks.
# It can be filled with interpolation between known positions
# Note that you can add this refiner to your MultiStepTracker pipeline
method = "constant" # tps / constant
full = False # Extrapolate position of the tracks on the all frame range and not just the track lifespan
tracks = ForwardBackwardInterpolater(method, full=False).run(video, tracks)
Forward propagation: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49/49 [00:00<00:00, 19312.24it/s]
Backward propagation: 100%|████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 49/49 [00:00<00:00, 17708.16it/s]
[28]:
# Visualize tracks existence in time
# Transform into tensor
tracks_tensor = byotrack.Track.tensorize(tracks)
print(tracks_tensor.shape) # N_frame x N_track x D
mask = ~ torch.isnan(tracks_tensor).any(dim=2)
plt.figure(figsize=(24, 16), dpi=100)
plt.xlabel("Track id")
plt.ylabel("Frame")
plt.imshow(mask)
plt.show()
torch.Size([50, 1164, 2])

Load or save tracks to files
[29]:
# Save tracks in ByoTrack format (compressed in a torch tensor)
byotrack.Track.save(tracks, "tracks.pth")
# Can be reload with
tracks = byotrack.Track.load("tracks.pth")
[30]:
# We also provide IO with Icy software
from byotrack import icy
icy.save_tracks(tracks, "tracks.xml") # Note that holes should should be filled first with the ForwardBackwardInterpolater
# You can (re)load tracks from icy with
tracks = icy.load_tracks("tracks.xml")